最近发现越来越多的网站喜欢使用自动提取标签栏,如小编常去的糗事百科网站就有一个,截图如下:
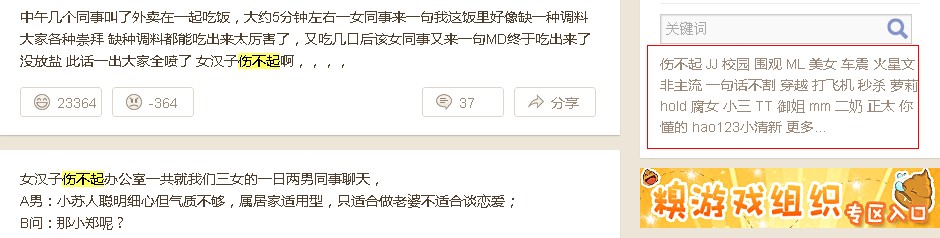
如上图。大家看右边部分,搜索框下方就是一个自动提取的标签栏。通过点击这些出现频率比较高的关键词,用户可以看到所有出现过此关键词的帖子。结合站内搜索框来说,即成为一个强大的搜索工具。对于网站内容多,更新快,分类多等类型的网站来说,是比搜索框更便利的搜索工具,也将成为网页设计的潮流趋势之一。
虽然网页设计越来越便捷,但是这背后设计师所付出的努力却是艰辛的。我们看糗事百科一个看似很简单的网站,但是如果请专业的网站建设公司来制作的话,成本最低都要好几万。这也能解释为什么我们看起来不起眼的随手的一个工具,说不定都凝聚了大批的设计师长时间的努力结果。
这个自动提取标签的设计也是一样。小编研究了一段时间,搜索了很多资料,才得出比较简单一点的设置方法。实际上这个方法并非对所有的程序都有效,而只是对JAVA程序而言的。在此将此段程序贴上来与大家分享:
- import java.io.BufferedReader;
- import java.io.InputStreamReader;
- import java.net.URL;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class URLTest {
- /**
- * @param args
- * @throws URISyntaxException
- */
- public static void main(String[] args) throws Exception {
- URL url = new URL("http://www.ascii-code.com/");
- InputStreamReader reader = new InputStreamReader(url.openStream());
- BufferedReader br = new BufferedReader(reader);
- String s = null;
- while((s=br.readLine())!=null){
- s = GetLabel(s);
- if(s!=null){
- System.out.println(s);
- }
- }
- br.close();
- reader.close();
- }
- public static String GetContent(String html) {
- //String html = "
- 1.hehe
- 2.hi
- 3.hei
- String ss = ">[^<]+<";
- String temp = null;
- Pattern pa = Pattern.compile(ss);
- Matcher ma = null;
- ma = pa.matcher(html);
- String result = null;
- while(ma.find()){
- temp = ma.group();
- if(temp!=null){
- if(temp.startsWith(">")){
- temp = temp.substring(1);
- }
- if(temp.endsWith("<")){
- temp = temp.substring(0, temp.length()-1);
- }
- if(!temp.equalsIgnoreCase("")){
- if(result==null){
- result = temp;
- }
- else{
- result+="____"+temp;
- }
- }
- }
- }
- return result;
- }
- public static String GetLabel(String html) {
- //String html = "
- 1.hehe
- 2.hi
- 3.hei
- String ss = "<[^>]+>";
- String temp = null;
- Pattern pa = Pattern.compile(ss);
- Matcher ma = null;
- ma = pa.matcher(html);
- String result = null;
- while(ma.find()){
- temp = ma.group();
- if(temp!=null){
- if(temp.startsWith(">")){
- temp = temp.substring(1);
- }
- if(temp.endsWith("<")){
- temp = temp.substring(0, temp.length()-1);
- }
- if(!temp.equalsIgnoreCase("")){
- if(result==null){
- result = temp;
- }
- else{
- result+="____"+temp;
- }
- }
- }
- }
- return result;
- }
- }
其中:GetContent用来获取标签内容,而GetLabel则用于获取标签。
实际上,这是正则法则运用中的一种。小编所运用到的这个正则法则的表达式是:
<[^>]+>:这个正则表达式可以匹配所有html标签,可以100%匹配,但需要注意页面编码方式和读取的编码方式。另外一个表达式是>[^<]+<,这个可以匹配标签内容。但由于小编对于正则法则不是非常的精通,并且时间有限,只研究出了这一种。另外用于设置网页自动提取标签的还有htmlparse、sax、dom4j等,但至于哪个更好用,哪个实现起来更容易,就要大家自己去探索了。